React, AWS and Circle CI: Your deployment strategy


Deployment automation is always at the forefront of what we focus on when considering new technology. Leaning heavily on CircleCI I invest heavily in ensuring that code deployments happen automatically after being pulled into the mainline branch.
In this mini-series, we will walk through how to get a react application deployed in AWS on S3 using Cloudfront along with automatically deploying it through CircleCI.
Why spend time doing this?
When working with various clients, it's imperative to remove the steps between merging code and publishing the site live. Each of those manual steps you can eliminate reduces the potential for problems which might happen as you go to deploy.
Having confidence in your teams ability to push code, have it automatically tested, linted, built and deployed is a pretty awesome feeling!
CircleCI to the rescue!
There are a wide range of wonderful CI/CD technologies these days, personally I chose CircleCI a while back as it was simple to get going and had a "HOLD" job. CircleCI uses yaml config files to define your pipeline. Let's take a look at the config I've been using.
version: 2.1
orbs:
aws-cli: circleci/aws-cli@1.0.0
slack: circleci/slack@3.4.2Version 2.1 introduces orbs, reusable pieces of 3rd party abstractions. This article will speak specifically to deploying to AWS so we include the official aws cli. I enjoy seeing notifications when builds are initiated in slack channels, so I have also added the slack orb in.
The Jobs
Jobs are a series of steps in your continuous deployment process. They allow you to fail various parts of your build. We'll talk more about how they connect together below when we talk about workflows.
pre-build:
working_directory: ~/app
docker:
- image: circleci/node:14
steps:
- slack/notify:
color: '#0693E3'
message: 'Build Initiated.'
webhook: ###your webhook###
- checkout
- attach_workspace:
at: ~/app
- restore_cache:
key: node-v2-{{ checksum "yarn.lock" }}-{{ arch }}
- run: yarn install
- save_cache:
key: node-v2-{{ checksum "yarn.lock" }}-{{ arch }}
paths:
- node_modules
- persist_to_workspace:
root: ~/app
paths:
- node_modulesThe pre-build job is really meant to either restore or run your yarn installer. By saving/restoring cache, we can trim some time off of future builds. We Also notify your slack channel to let you know a build has started.
Each of the steps act as a progression circleci's runner will execute on, in sequence.
test:
working_directory: ~/app
docker:
- image: circleci/node:14
steps:
- checkout
- attach_workspace:
at: ~/app
- run: yarn run testTest is for running any of your tests that your package has. Since the previous step used a persist, we are able to re-attach the workspace and pick up from where we left off. This is nice to be able to isolate and fail at various parts in the workflow (below).
In this case, the only thing I have executing is test
The next job we have is build:
build:
working_directory: ~/app
docker:
- image: circleci/node:14
environment:
REACT_APP_MY_ENV_VAR: 'foo_bar'
steps:
- checkout
- attach_workspace:
at: ~/app
- run: yarn run release
- run:
name: GZIP Data
# We do the below commands to take file.ts.gz and file.ts and overwrite file.ts with the file.ts.gz.
# S3, nor our bundlers want to represent a file with .ts.gz so below we set the headers
# to do that for us.
command: |
yarn run gzipall
echo ${CIRCLE_SHA1} > build/current-git-commit.txt
find build -maxdepth 4
echo ===============================
for old in build/*.gz; do mv $old ${old%%.gz*}; done
for old in build/static/css/*.gz; do mv $old ${old%%.gz*}; done
for old in build/static/js/*.gz; do mv $old ${old%%.gz*}; done
for old in build/static/media/*.gz; do mv $old ${old%%.gz*}; done
find build -maxdepth 4
- persist_to_workspace:
root: .
paths:
- build
Here is the bulk of what's starting to happen, first off we're not adding additional environment variables to the build script (ie; webservice, analytics, or other configurable variables).
Lastly here, we have a command called gzipall executing. With this gzip all, the first thing we want to do is at least tag our git commit from the CIRCLE_SHA1 environment variable. This could help us with debugging in production, an dis a nice to have.
Next up, we are looping through all the files that we have and removing the .gz parameter. We want S3 to serve these up as normal files that only have the gzip headers applied, but not actual file names.
We also do this because in our react app we are likely referencing these items without the gzip extension. If we skipped this step, even our bundler would return out a bunch of invalid references.
At the end, we persist the build path so we can move on.
Time for Deploying!
Our last step is deploying the application to S3. The executor here is something we are taking advantage of from the aws-sdk orb. the aws-sdk orb expects a few environment variables which you'll want to set through circleci instead of checking them in. We do not want to be checking in credentials to a source repository, as this would lead to leaking security credentials to anyone in your system.
In your project settings, you can click "Add Environment Variable" and add away through a dialog like this:
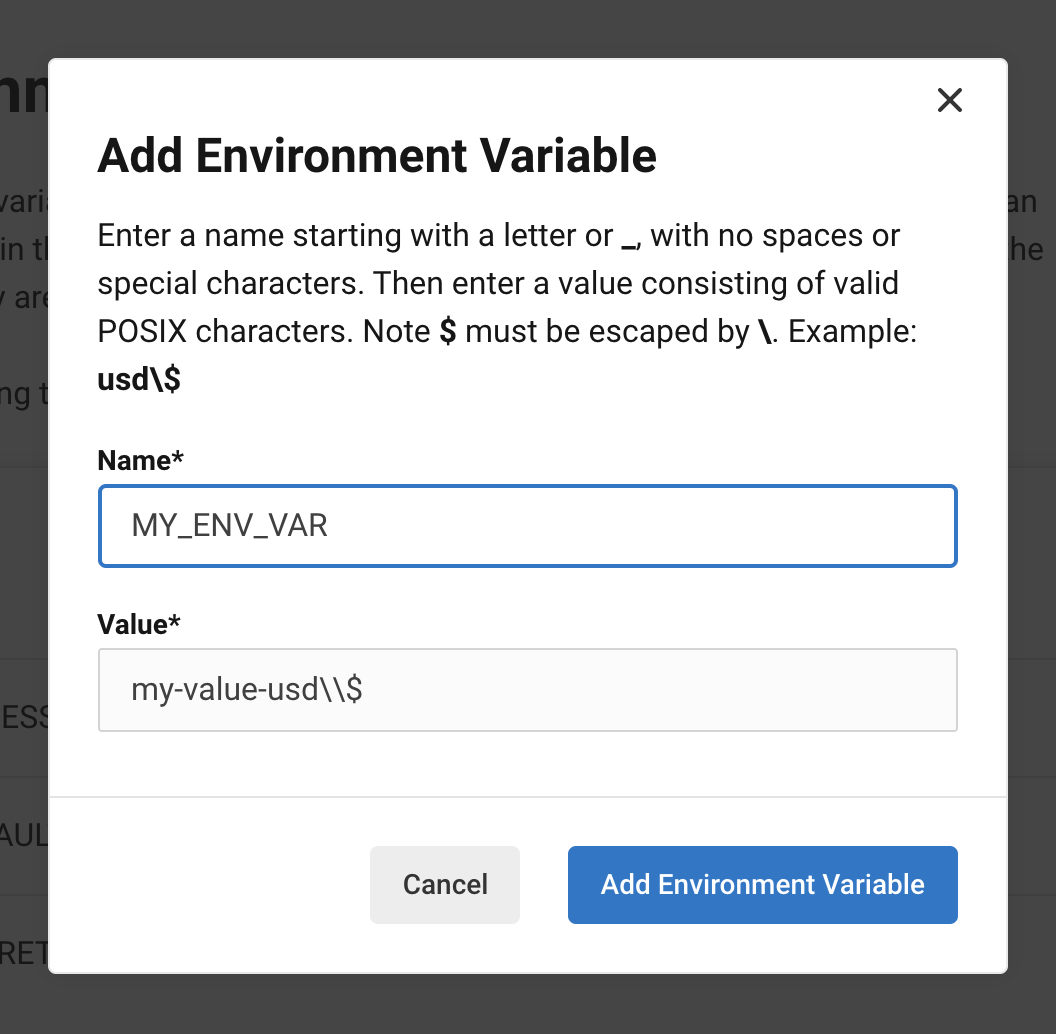
The configuration step for the deploy job:
deploy:
executor: aws-cli/default
working_directory: ~/app
steps:
- checkout
- attach_workspace:
at: ~/app
- aws-cli/setup:
profile-name: default
- run:
name: Upload file to S3
command: |
aws s3 sync ~/app/build s3://YOUR_BUCKET --metadata-directive REPLACE --acl public-read --cache-control max-age=0,no-cache,no-store,must-revalidate --exclude "index.html" --exclude "*.css" --exclude "*.js" --exclude "*.svg" --exclude ".map"
aws s3 sync ~/app/build s3://YOUR_BUCKET --metadata-directive REPLACE --acl public-read --cache-control public,max-age=31536000,immutable --exclude "*" --include "*.css" --include "*.js" --include "*.svg" --content-encoding gzip
aws s3 cp ~/app/build/index.html s3://YOUR_BUCKET --metadata-directive REPLACE --cache-control max-age=0,no-cache,no-store,must-revalidate --content-type text/html --acl public-read --content-encoding gzip
- slack/notify:
color: '#0693E3'
message: 'Deployed to preview!'
webhook: WEBHOOK_URLThese commands will bring in all of our files, apply the correct headers then let our slack channel know deployment has successfully completed.
One thing to note here is our last command of copying and overwriting our index.html file. Since this is our index.html file, we do not want it to cache.. ever. We want to tell both the browser AND cloudfront of this. We will essentially use our index.html file to cache bust and invalidate JS files (vs calling cloudfront invalidations costing us $) by setting it to public-read and at a max-age of 0.
The Workflows
So far we have built up our jobs, but now we need to assemble them into a workflow that best suits our needs to deploy. Here's an example of how I've constructed the above ones into a workflow:
workflows:
version: 2
build_and_deploy:
jobs:
- pre-build
- test:
requires:
- pre-build
- build:
requires:
- test
- deploy:
requires:
- build
filters:
branches:
only: main
- prod_build:
requires:
- deploy
- hold:
type: approval
requires:
- prod_build
- prod_deploy:
requires:
- holdI want every commit to essentially work it's way up to building. This way I know that my Pull Requests have successfully passed linting and can build. Once complete, and merged into main, the deploy task can execute.
Deploying, once successful, will automatically kick off the prod_build (not mentioned above, but nearly identical to build job). This is where we can then use the magical hold command.
Hold will initiate the lovely UI which forces a manual click in order to deploy production like:
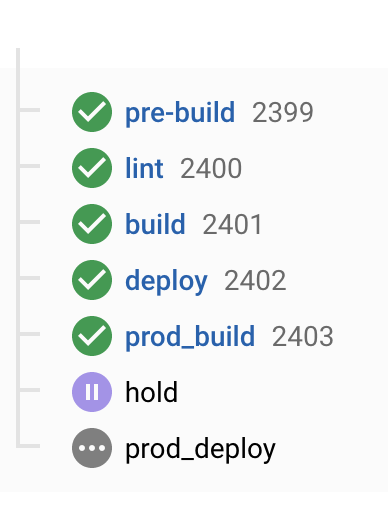
Once confirming your hold action, you'll be tagged as the individual whom chose to confirm it and your prod deploy will initiate!
Best of luck with your CI/CD automation :)